We introduce Latent Action Pretraining for general Action models (LAPA), the first unsupervised method for pretraining Vision-Language-Action (VLA) models without ground-truth robot action labels. Existing Vision-Language-Action models require action labels typically collected by human teleoperators during pretraining, which significantly limits possible data sources and scale. In this work, we propose a method to learn from internet-scale videos that do not have robot action labels. We first train an action quantization model leveraging VQ- VAE-based objective to learn discrete latent actions between image frames, then pretrain a latent VLA model to predict these latent actions from observations and task descriptions, and finally finetune the VLA on small-scale robot manipulation data to map from latent to robot actions. Experimental results demonstrate that our method significantly outperforms existing techniques that train robot manipulation policies from large-scale videos. Furthermore, it outperforms the state-of- the-art VLA model trained with robotic action labels on real-world manipulation tasks that require language conditioning, generalization to unseen objects, and semantic generalization to unseen instructions. Training only on human manipulation videos also shows positive transfer, opening up the potential for leveraging web-scale data for robotics foundation model.
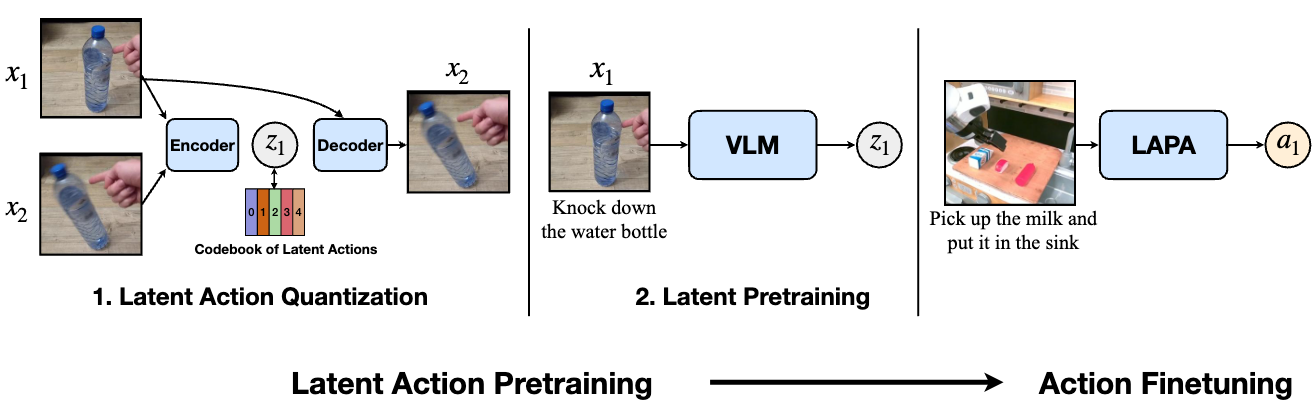
LAPA is divided into two stages: Latent Action Quantization and Latent Pretraining. First, we use a VQ-VAE based objective to capture the discretized latent delta information between consecutive frames in a video. Next, a pretrained VLM is trained to predict the latent action designated by the encoder of the Latent Action Quantization model, given the current image and the language instruction. After Latent Pretraining, we finetune the VLA model on a small number of ground-truth action-labeled trajectories to map the latent space to the actual action space.
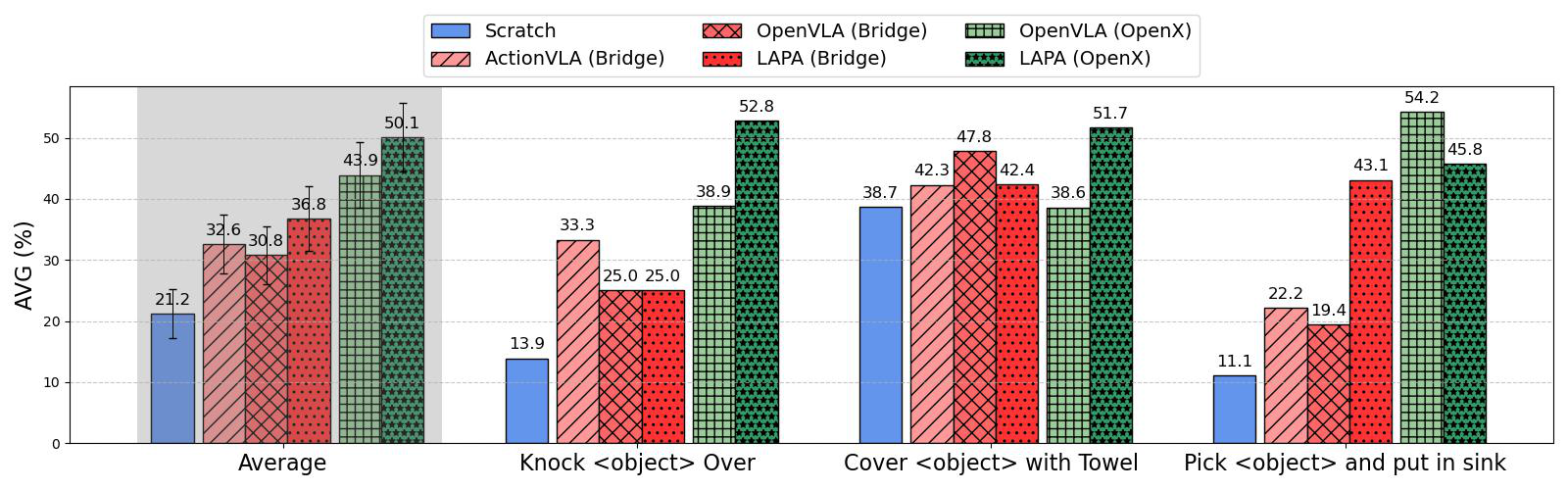
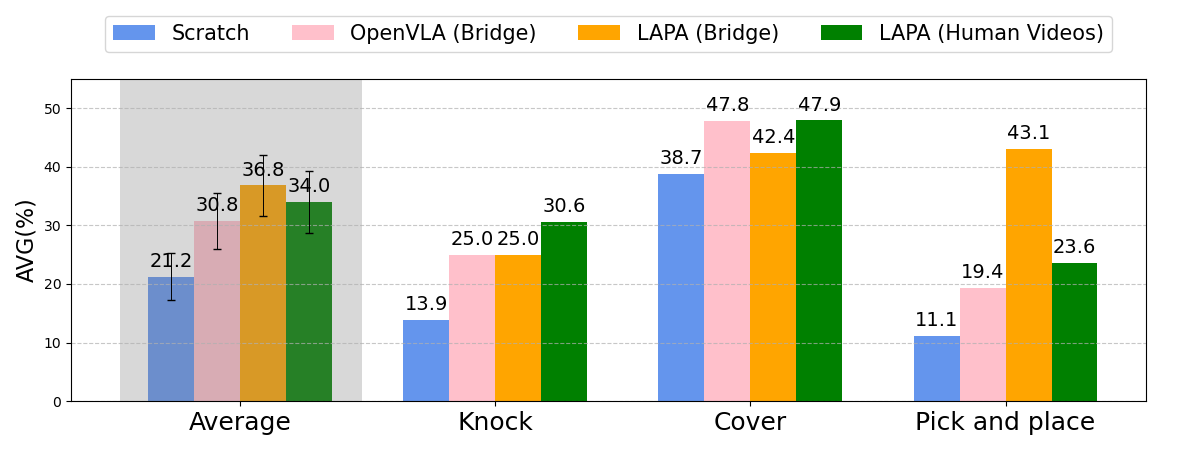
To extend LAPA on human manipulation videos where the action labels are not present, we pretrain LAPA on Something-Something V2 Dataset (220K videos) and fine-tune on robot embodiment. The embodiment gap for this case is extreme (human to robot). Surprisingly, we can see that LAPA trained with human videos outperforms OpenVLA (Bridge) on average. Despite the larger embodiment gap for LAPA (Human to robot vs. Robot to robot), it learns a better prior for robot manipulation. This result highlights the potential of raw human manipulation videos from the web compared to expensive robot manipulation data, which requires time-intensive teleoperation to collect. We expect that applying our approach on large-scale internet videos (e.g., YouTube videos) could unlock the potential for large-scale pretraining of a generalist action foundational model, similar to foundational models in Natural Language Processing or Computer Vision.
For interpretation, we condition the current image observation and each latent action on the decoder of the latent action quantization model, and present the reconstructed images.
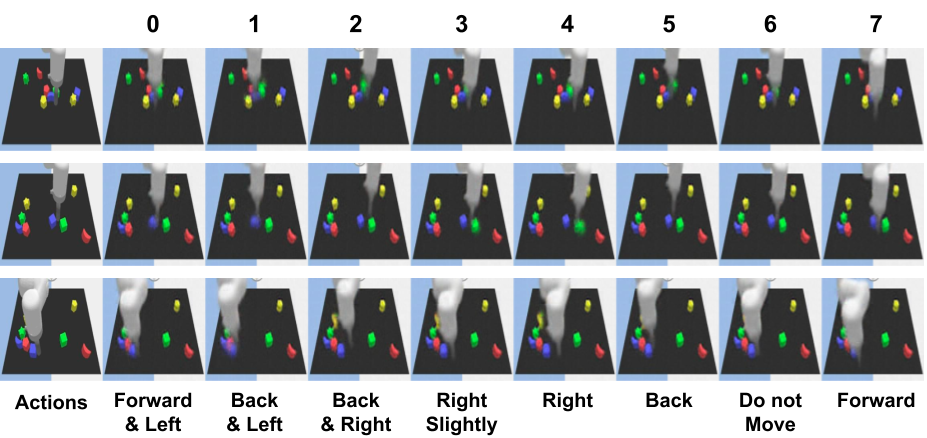
We observe that each latent action can be mapped into a semantic action of the robot arm. For example, latent action 0 corresponds to moving a bit left and forward.

For human videos where the camera view changes in a single video, we observe that each latent action can be mapped into a semantic action including camera movements. For example, latent action [3,5,2,7] corresponds to moving the camera a bit down while [4,2,0,0] corresponds to moving the camera slightly up.

For multi-embodiment setting, we observe that each latent action can be mapped into a similar semantic action similar semantic action even though the embodiments are different. This supports our previous claim that latent actions are learned in a shared representation space, regardless of the embodiment or dataset, facilitating stronger positive transfer across diverse datasets.


We analyze the coarse-grained planning capability of LAPA through a closed-loop rollout by using LAPA model that has only undergone pretraining. When conditioned on the current observation and the instruction to "take the broccoli out of the pot", LAPA generates robot trajectories that successfully reaches for the broccoli, moves down to grab it, and, as the arm moves away from the pot, the broccoli disappears. This shows the potential for LAPA as a general-purpose robotic world model, not only predicting actions but also the outcomes of the actions.


























Both OpenVLA and LAPA struggles on Bi-manual robot setup, indicating much room for improvement.
@misc{ye2024latentactionpretrainingvideos,
title={Latent Action Pretraining from Videos},
author={Seonghyeon Ye and Joel Jang and Byeongguk Jeon and Sejune Joo and Jianwei Yang and Baolin Peng and Ajay Mandlekar and Reuben Tan and Yu-Wei Chao and Bill Yuchen Lin and Lars Liden and Kimin Lee and Jianfeng Gao and Luke Zettlemoyer and Dieter Fox and Minjoon Seo},
year={2024},
eprint={2410.11758},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2410.11758},
}